多媒体技术
1. 简要说明离散媒体与连续媒体的区别,自然媒体和合成媒体的区别
感觉媒体和表示媒体 (交互形式)
| 类型 | 定义 | 例子 |
|---|---|---|
| 感觉媒体 | 人—人或者人—机交换信息的形式。由于人们通过视觉、听觉器官等感知信息, 因此称为可感知形式 | 文字、数据、声音、图形、图像 |
| 表示媒体 | 计算机内部或者机—机交换信息的形式。由于计算机以二进制编码的形式表示文字、图像、声音等,所以称为数字媒体�形式 | 语言编码、电报码、条形码 |
离散媒体和连续媒体 (是否有时间轴)
| 类型 | 定义 | 例子 |
|---|---|---|
| 离散媒体 | 离散媒体是独立于时间的媒体 | 文本,图形,图像 |
| 连续媒体 | 连续媒体(时基媒体)是依赖于时间的媒体,不仅用一系列值表示,而且要指出相应值出现的时间,信息的表示与时间有关 | 声音,视频 |
自然媒体和合成媒体 (按生成属性分类)
| 类型 | 定义 | 例子 |
|---|---|---|
| 自然媒体 | 指客观世界存在的景物、声音等,经过特定的设备,进行数字化和编码处理之后得到的数字媒体 | Wave sound , Bitmap image , Digital video |
| 合成媒体 | 指以计算机为工具、采用特定符号、语言或算法表示的、由计算机生成(合成)的文本、音乐、语音、图象和动画 | MIDI 音乐,TTS,graphics,computer animation |
2. 西文字符如何编码?ISO646与ISO8859有什么区别?
ASCII
计算机中使用得最广泛的西文编码字符集:美国标准信息交换码(American Standard Code for Information Interchange, 简称ASCII码),后来被批准为ISO-646-US标准
ASCII字符集中
- 32个控制字符 + 96个可打印字符
- 采用7位二进制进行编码
ISO-8859
该编码是在 ASCII 编码的基础上扩展出来的,但它仍然是单字节编码 (单 8 位代码空间),总共只能表示 256 个字符。
既然 ASCII 只能表示 128 个字符,显示是不能完全表示完的,所以 ISO-8859-1 扩展了 ASCII 编码,在 ASCII 编码之上又增加了西欧语言、希腊语、泰语、阿拉伯语、希伯来语对应的文字符号,它是向下兼容 ASCII 编码的。
3. GB2312国标汉字编码包括多少汉字和符号?区位码、交换码与机内码有什么区别和联系?
GB2312字符集由三个部分构成:
- 字母、数字和各种符号,包括拉丁字母、俄文、日文平假名与片假名、希腊字母、汉语拼音等共682个(统称为GB2312图形符号)
- 一级常用汉字,共3755个,按汉语拼音排列
- 二级常用字,共3008个,因不太常用,所以按偏旁部首排列
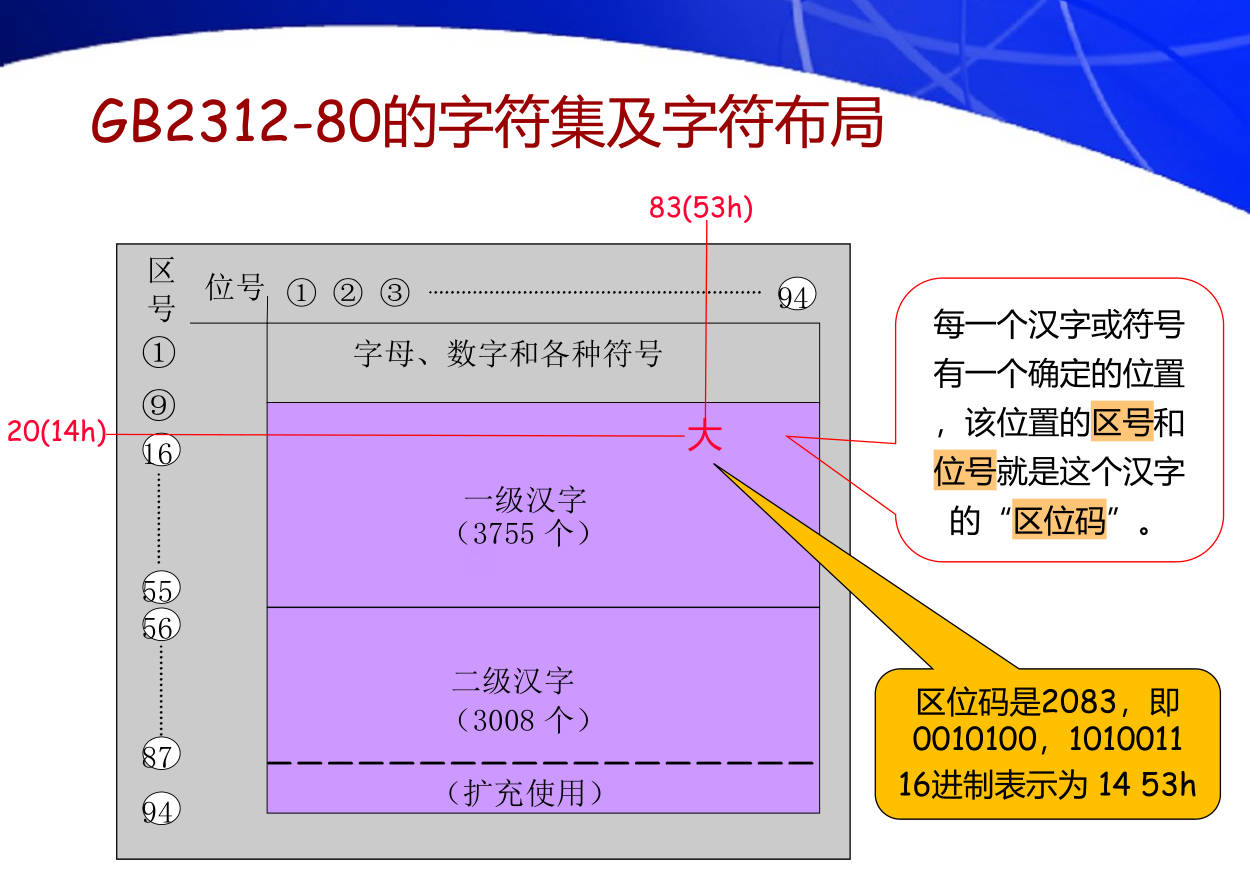
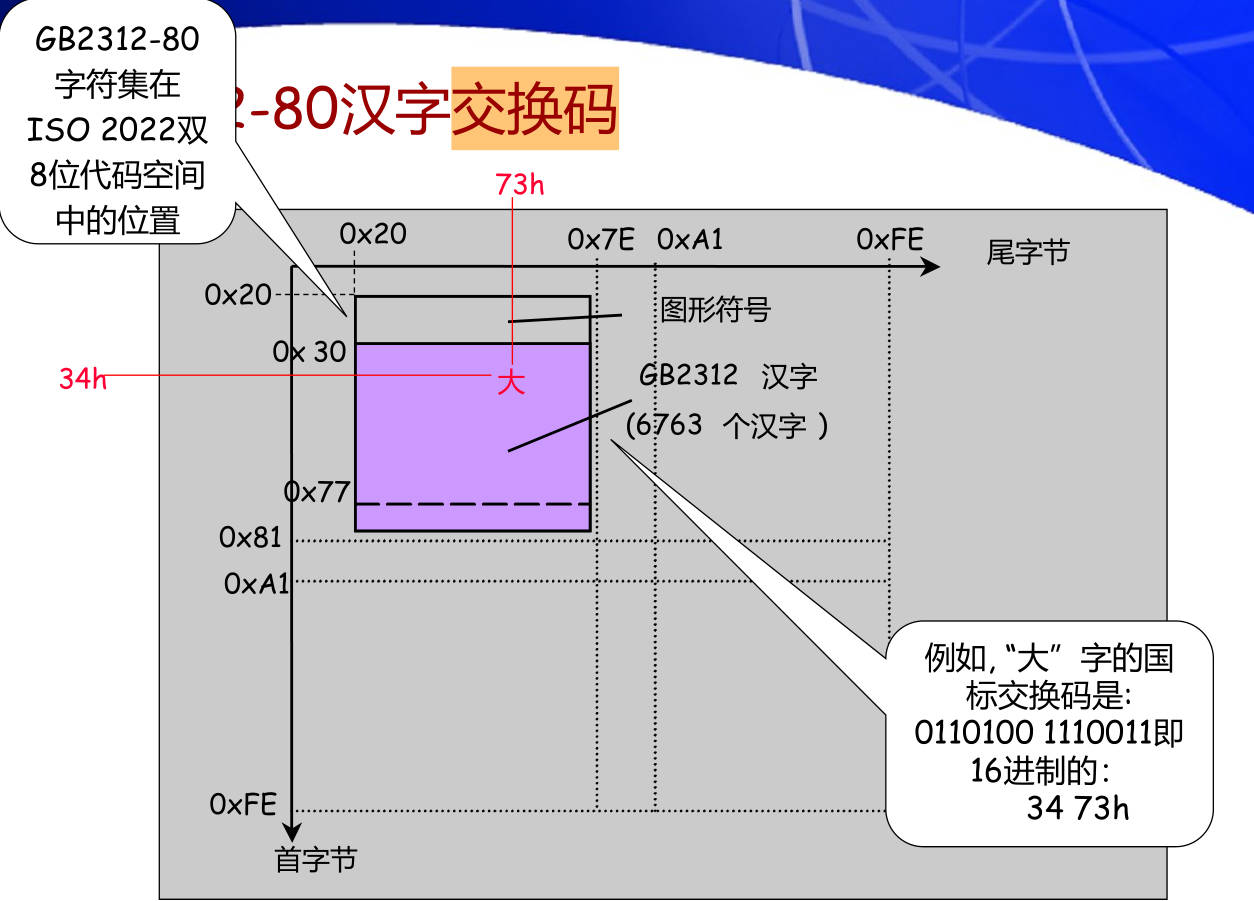
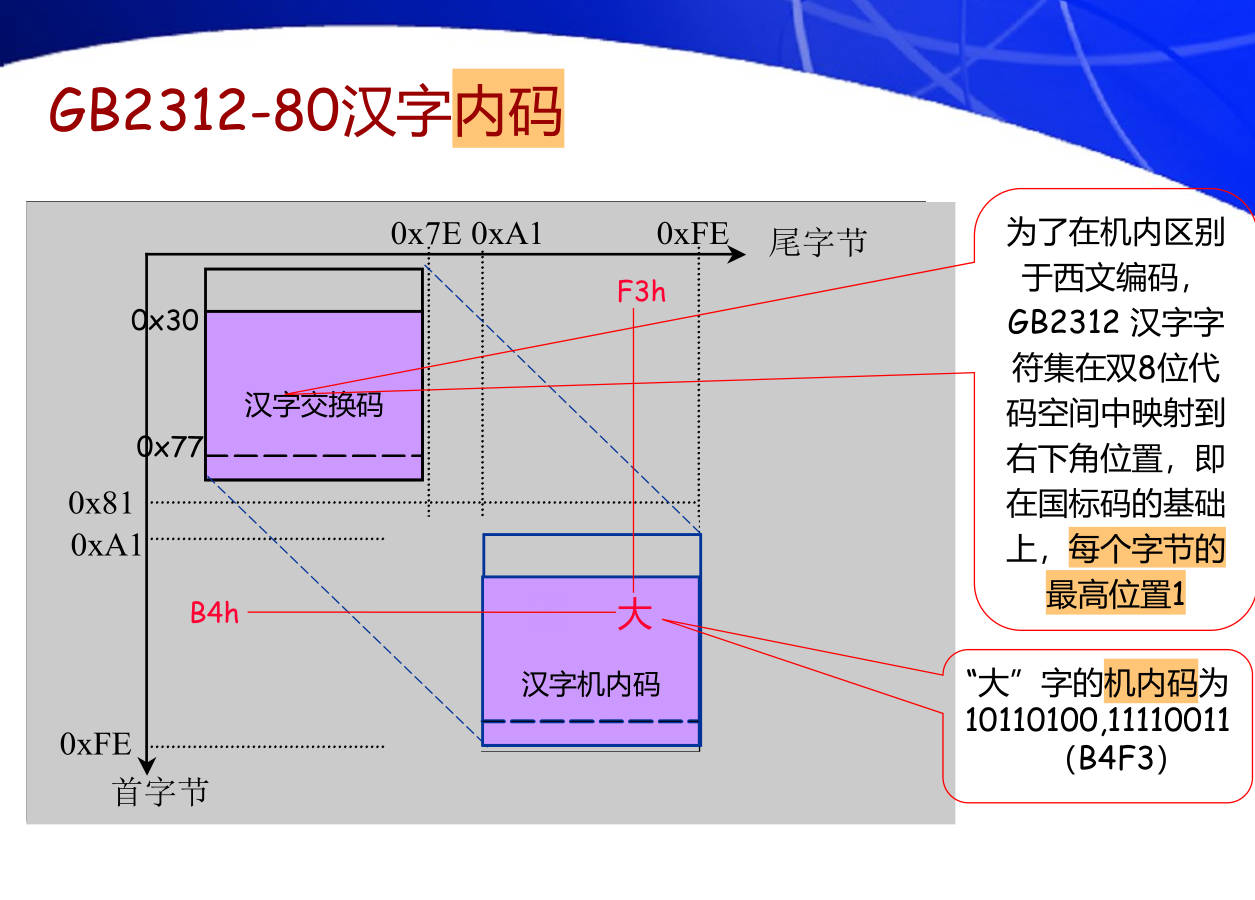
其转换关系如下:
- 区位码两个字节分别加上 32 可以得到国标码
- 国标码两个字节分别加上 128 可以得到机内码
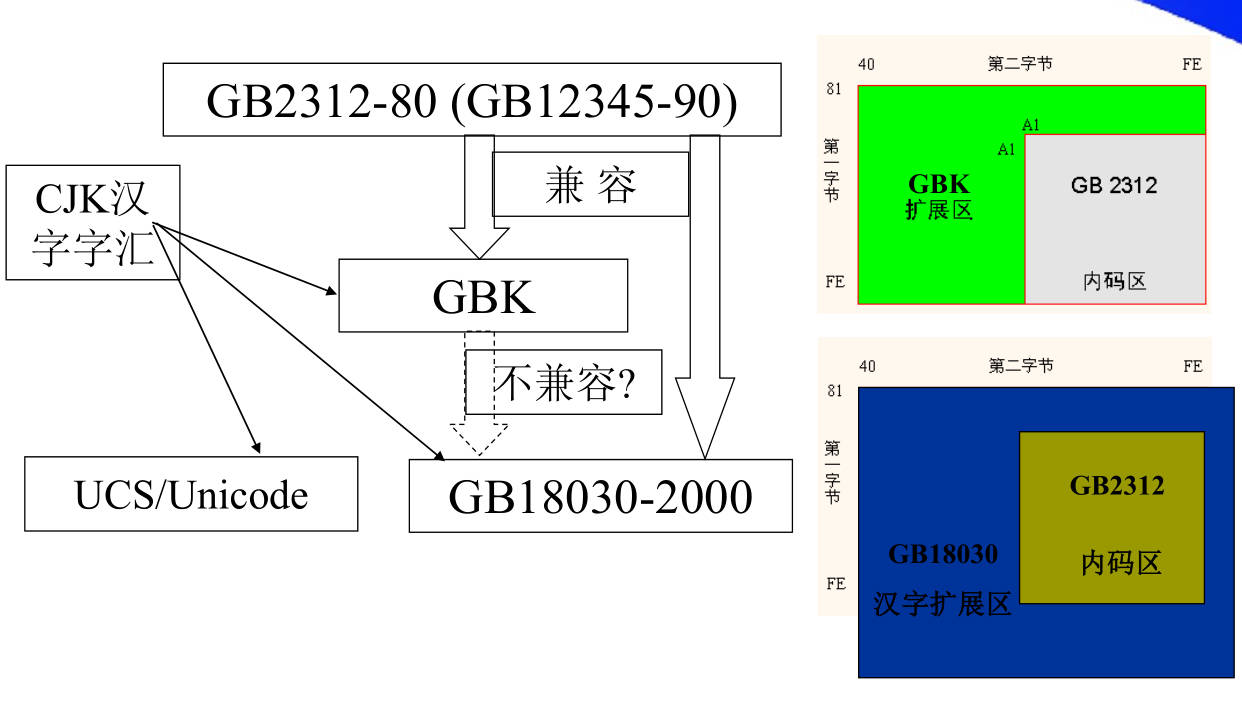
4. CJK是什么?GBK是什么?两者有什么关系?GBK与GB2312之间是什么关系?
CJK 和 GBK 的关系: GBK 收录了全部的 CJK 汉字和符号, 并有所补充
GB2312 和 GBK 的关系: GBK 与 GB2312-80 保持向下兼容,后者只包含简体字
CJK(中日韩)统一汉字字符集
- 所谓CJK统一汉字编码, 是指不论国家和地区,不论汉字的字义有无区别,只要字形相同,该汉字就只有一个代码
- CJK字符集以现有各国和地区的标准字符集作为源字符集,将其中的汉字按统一的认同规则进行认同/甄别后,生成涵盖各源字集并按东亚著名的四大字典(康熙字典、大汉和字典、汉语大字典及大字源)的页码/字位综合排序(按部首—笔画数目)排序,构成共27,484个汉字组成的大字符集
- 经过中、日、韩、越、新的力争,国际标准化组织在Unicode编码体系中给汉字划出了9万多个码位,各国将对CJK汉字字符集作进一步的扩充
GBK《汉字内码扩展规范》
GBK全称《汉字内码扩展规范》(1995年)
- 向下与 GB 2312 编码兼容
- 向上准备向ISO 10646.1 国际标准过渡,是一个承上启下的标准
GBK 规范收录了 ISO 10646.1 中的全部 CJK 汉字和符号,并有所补充
- GB 2312中的全部汉字(GBK/2)
- 其他CJK汉字和增补的汉字(GBK/3和GBK/4),共21003个汉字
- 另外还有883个图形符号(GBK/1, GBK/5
特点
- 汉字数目多,共21003个
- 简体和繁体汉字在同一个字符集中
- 包含了中、日、韩认同的全部CJK汉字
- 双字节编码,第1字节的最高位必为“1”,第2字节的最高位不一定是“1”
- 与GB2312-80保持向下兼容
- 与ISO10646中的汉字字汇兼容,代码不兼容
字汇(repertoire):编码字符集中有哪些字符
5. UCS编码是什么?其意义何在?目前进展如何?有哪些具体的实现方案?
ISO/IEC 10646 即“统一编码字符集”(Universal Coded Character Set,简称UCS), 相应的工业标准称为“Unicode”,两者完全兼容。
它的设计目标是实现所有字符在同一字符集中等长编码、同等使用的真正多文种信息处理, 使得各个国家和民族语言文字都能方便地进行计算机通信,特别是允许能同时使用任意多种语言文字
UCS 用 4 个字节编码 1 个字符
UTF-16
UTF-16 是变长编码, 既有 2 字节形式又有 4 字节形式, 能表示 UCS 种所有字符
读取UTF-16比特流时, 2 个字节一读:
- 如果当前两字节大于0xD800, 小于0xDCFF, 那么说明是 4 字节形式,需要再读 2 个字节
- 其他情况则说明是 2 字节形式
UTF-8
首先读取第一个字节:
- 若最高位是 0, 则该字符使用 1 个字节编码
- 若从最高位开始的顺序是 110, 则该字符使用 2 个字节编码
- 若从最高位开始的顺序是 1110, 则该字符使用 3 个字节编码
- 若从最高位开始的顺序是 11110, 则该字符使用 4 个字节编码
6. 什么是GB18030-2000汉字编码标准?它与GBK、GB2312之间是什么关系?与UCS编码是什么关系?
GB18030-2000,全称《信息技术 中文编码字符集》,是中华人民共和国国家标准所规定的变长多字节字符集。其对 GB 2312-1980 完全向后兼容,与 GBK 基本向后兼容,并支持Unicode(GB 13000)的所有码位。GB 18030-2005共收录汉字70,244个。
- 与现有的绝大多数汉字操作系统、中文平台在计算机内码一级兼容,即与国家标准GB 2312信息处理交换码所对应的事实上的内码标准兼容
- 在字汇上支持 UCS/Unicode (GB13000.1-1993)的全部 CJK 统一汉字字符和全部CJK统一汉字扩充A的字符。
- 同时收录了藏文、蒙文、维吾尔文等主要的少数民族文字,为推进少数民族的信息化奠定了坚实的基础。
- 该标准由��信息产业部和国家质量技术监督局在2000年联合发布的,并在2001年开始执行。 最新标准为2005版
与 UCS 编码的关系
- GB 18030-2000,兼容 Unicode 3.0 中日韩统一表意文字(即扩展A区),共收27533个汉字;2000年3月17日发布
- GB 18030-2005,更新至 Unicode 3.1 中日韩统一表意文字(即扩展B区),并增加少数民族包括朝鲜文、蒙古文(包括满文、托忒文、锡伯文、阿礼嘎礼文)、德宏傣文、藏文、维吾尔文/哈萨克文/柯尔克兹文和彝文的文字。共有70244个汉字;2005年11月8日发布、2006年5月1日实施
汉字编码小结
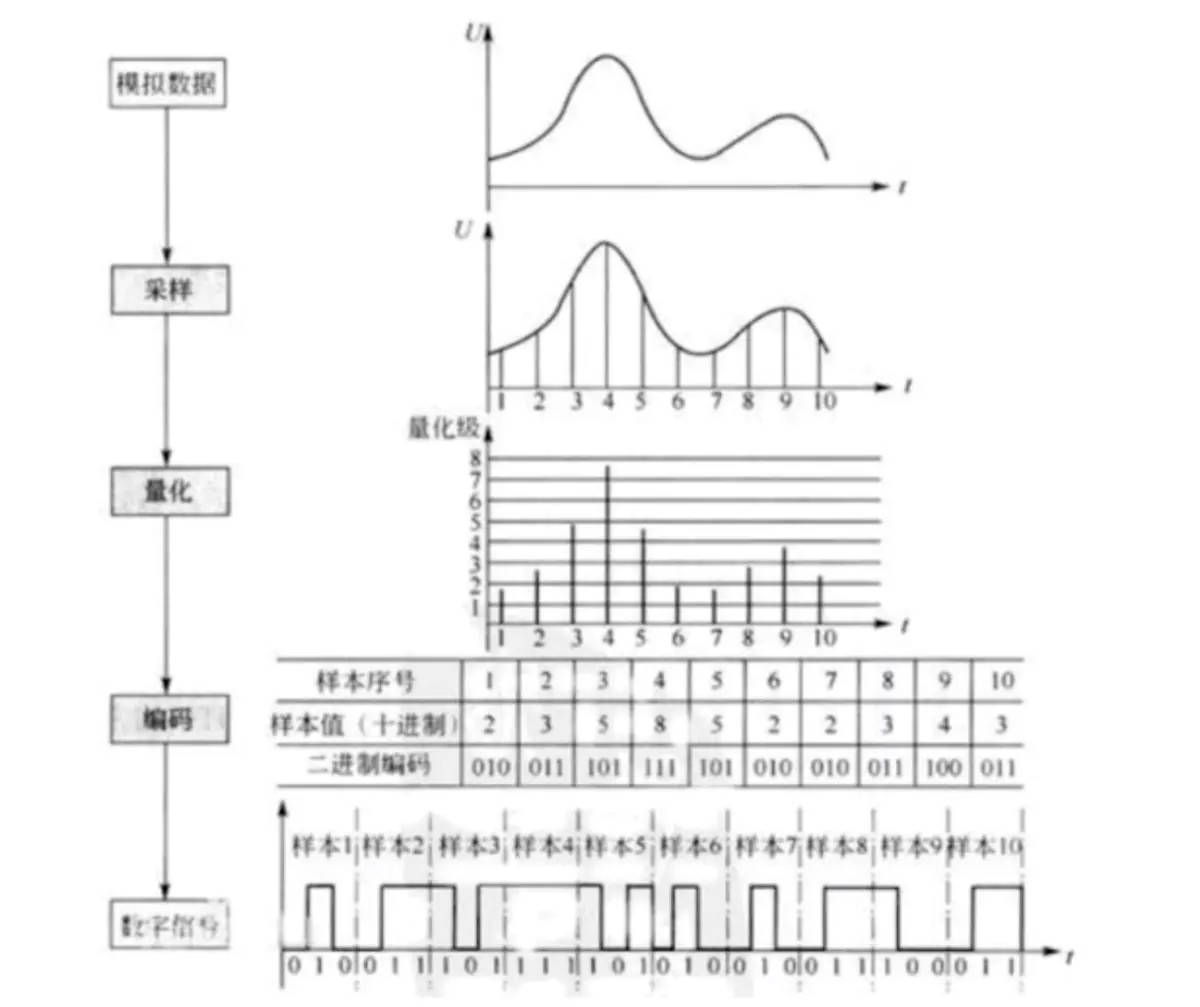
7. 什么是取样?什么是取样定理?
取样通常指周期取样, 也即用相同的时间间隔 (空间间隔) 采样模拟信号, 从而得到离散时间信号。 周期取样的时间间隔称为取样周期, 取样周期的倒数称为取样频率。
- 对于音频而言,每隔多少毫秒取一个样本
- 对于图片而言,在空间轴上将其离散
能够无失真地恢复出原始信号的最低取样频率称为Nyquist取样频率。取样定理表明:Nyquist取样频率为原始信号最高频率的2倍。
8. 简要叙述模拟声音信号数字化的步骤和每个步骤的作用
取样
对连续信号按一定的时间间隔取样。奈奎斯特取样定理认为,只要取样频率大于等于信号中所包含的最高频率的两倍,则可以根据其取样完全恢复出原始信号,这相当于当信号是最高频率时,每一周期至少要采取两个点。但这只是理论上的定理,在实际操作中,人们用混叠波形,从而使取得的信号更接近原始信号。
量化
取样的离散音频要转化为计算机能够表示的数据范围,这个过程称为量化。量化的等级取决于量化精度,也就是用多少位二进制数来表示一个音频数据。一般有8位,12位或16位。量化精度越高,声音的保真度越高。
量化精度既决定了取样值的动态范围,也决定着所引入的噪声大小。
编码
对音频信号取样并量化成二进制,但实际上就是对音频信号进行编码,但用不同的取样频率和不同的量化位数记录声音,在单位时间中,所需存贮空间是不一样的。波形声音的主要参数包括:取样频率、量化位数、声道数、压缩编码方案和数码率等。波形声音的码率一般比较大,所以必需对转换后的数据进行压缩。
9. 数字化波形声音的主要参数有哪些?其中"码率"的含义和计量单位是什么?
数字化波形声音的主要参数有:
- 取样频率 (sampling frequency)
- 量化位数 (quantization bits)
- 声道数目 (number of sound channels)
- 压缩编码方法 (encoding method ( compression method ))
- 码率或比特率 (bit rate),每秒钟的数据量
码率或比特率指的是单位时间内传输送或处理的比特的数量,也就是每秒钟的数据量。
其常见单位为比特/秒(bit/s或bps)、千比特/秒(kbit/s或kbps,k=)或兆比特/秒(Mbps,M=)。
码率计算公式:
码率 = 取样频率 * 量化位数 * 声道数
比如采样率44.1kHz,量化位数(采样大小)为16bit,双声道PCM编码的WAV文件:
码率=44.1hHz*16bit*2=1411.2kbit/s。
那么录制1分钟的音乐的大小为(1411.2 * 1000 * 60) / 8 / 1024 / 1024 = 10.09M。
10. 数字语音压缩编码的三种方法和优缺点
| 类型 | 优点 | 缺点 | 例子 |
|---|---|---|---|
| 波形编码 (Perception model-based compression) | 通用、音频质量较高 | 很难获得较大的压缩比 | PCM, ADPCM, SBC |
| 参数编码,源编码 (Production model-based compression) | 压缩比较大 | 信号源必须已知, 语音质量较差 | LPC |
| 混合编码(Hybrid compression) | 既利用了语音的生成模型,减少了传输码率,又使解码的语音产生接近原始语音的波形,以保留说话人的各种自然特征 | CELP |
11. 人的听觉系统对于声音的响度和音调的感知有什么特点?什么是掩蔽效应?频域掩蔽和时域掩蔽分别是什么含义?它们怎样在压缩声音数据中起作用?
- 对响度的感知
- 人的听觉系统存在一个听觉阈值电平,低于这个电平的声音信号就听不到 (存在听阈和痛阈)
- 听觉阈值的大小随声音频率的改变而变化,大多数人的听觉系统对2 kHz~5 kHz之间的声音最敏感
- 声音是否能听到取决于声音的频率及强度(是否大于该频率对应的听觉阈值)
- 每个人的听觉阈值也不同
- 对音调的感知
- 人们对音调(音高)的主��观感觉, 单位是“美”(Mel)
- 主观感觉的音调与频率之间并不是线性关系:
- 人耳对频率的感知范围在 20 Hz ~ 20000 Hz
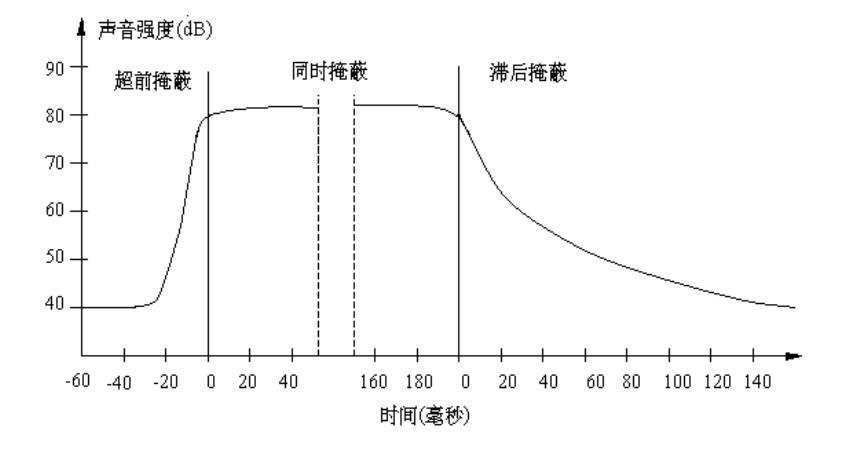
掩蔽效应
一种频率的声音阻碍听觉系统感受另一种频率的声音的现象称为掩蔽效应。前者称为掩蔽声音(masking tone, masker),后者称为被掩蔽声音(masked tone, maskee)。
频域掩蔽
- 强纯音会掩蔽频率与其靠近的同时发声的弱纯音,这种特性称为频域掩蔽,也称同时掩蔽(simultaneous masking)。
- 弱纯音离强纯音越近就越容易被掩蔽
- 低频纯音可以有效地掩蔽高频纯音,但高频纯音对低频纯音的掩蔽作用则不明显
- 掩蔽效应的作用范围和大小,与声强及频率有关,频率越高、声音越强,掩蔽效应越大
时域掩蔽
在时间上相邻的声音相互之间也有掩蔽现象,称为时域掩蔽。时域掩蔽的主要原因是人的大脑处理信息需要花费一定的时间。
MPEG-1 音频是如何利用声音的掩蔽效应来进行编码
MPEG-1 声音数据以“帧”为单位进行编码处理。使用的时间-频率变换部件将时间域上的样本转换到 32 个频带的频率域上,通过心理声学模型计算出每个子频带的信掩比,同时根据输出码率决定每一帧样本的比特总数 A 在不超过总数 A 的前提下,使这一帧的总掩蔽与噪声之比( MNR )最小
12. MPEG-1 声音编码有哪些主要性能?
- 编码器输入:
- 取样频率:32kHz、44.1kHz 或 48kHz
- 量化精度:16 位
- 数字声音信号带宽: 20-20kHz
- 编码器输出:
- 码率:32-384 kbps
- 格式:MPEG-1格式
- 提供三个独立的压缩层次:
- 支持4种不同的模式:
- 单通道(Single channel)
- 双通道(Dual channel,二个独立的声音信号编码在一个比特流中)
- 立体声(Stereo, 左右声道的信号分别编码在一个流中)
- 联合立体声(Joint stereo,利用左、右声道信号的相关性,降低输出比特流的码率)
- 编码后的数据流支持循环冗余校验 CRC (cyclic redundancy check)
- 支持在数据流中添加其它附加信息
13. MPEG-1 音频压缩的 3 个不同层次(layer)有什么联系和区别,它们的主要性能和参数如何?
- 层 1: 每帧一个样本组、子带频宽相等、每帧 32×12=384 个样本、仅用到频率掩蔽效应。
- 层 2: 每帧三个样本组、子带频宽相等、每帧 32×12×3=1152 个样本、不仅用到频率掩蔽效应,还用到时域掩蔽效应。
- 层 3: 子带频宽与临界频宽相似, 用到频率掩蔽效应和时域掩蔽效应, 考虑到立体声冗余, 采用 Huffman 编码。
14. MPEG-2 在那些方面对 MPEG-1 Audio 作了扩展?
- 增加了 16 kHz, 22.05 kHz 和 24 kHz 采样频率声音的处理,
- 扩展了编码器的输出速率范围,由 32
384 kbps扩展到 8640 kbps, - 增加了声道数,支持 5.1 声道和 7.1 声道的环绕立体声
15. 什么叫 MIDI?原理是什么?
MIDI 是乐器数字化接口(Musical Instrument Digital Interface)的缩写。所以说 MIDI 并不是一个实在的东西,而是一个国际通用的标准接口。通过它,各种 MIDI 设备都可以准确传送 MIDI 信息
16. 颜色的机理是怎样的?在计算机中如何描述颜色?不同应用场合分别使用什么样的颜色模型?Jpeg 和 Jpeg2000 的颜色空间是什么?
感知颜色三要素
- 光的存在(光源色)
- 物体的表面特性(物体色)
- 人眼的视觉功能
颜色三要素
- 色调:指颜色的外观,用于区别颜色的名称或颜色的种类,决定于光的波长
- 饱和度: 也称为纯度或彩度,指彩色的深浅或鲜艳程度,通常指彩色中白光含量的多少
- 亮度: 表示某种颜色在人眼视觉上引起的明暗程度,与光的强度有关
颜色模型
颜色模型的分类:
- 加色模型: 颜色由光照射生成,只要有光色叠加,颜色就越来越亮,最终称为白色
- 减色模型: 颜色是颜料吸收了光线产生,要表现一种颜色,就要想办法把其他颜色过滤掉,当墨水越来越浓,白色也被遮盖的越来越彻底,当CMY三种颜色遮满纸面时,这时显示出的颜色就是黑色,也就是在彻底失去所有颜色的状态。
HSL和HSV(或称HSB)都是RGB模式下的模型,适用的都是加色原理,也就是所谓的“发光”产生颜色
| 模型 | 含义 | 应用场合 |
|---|---|---|
| RGB 模型 | 红(Red)、绿(Green)、蓝(Blue) | 显示器、投影仪、扫描仪、数码相机 |
| CMY(K) 模型 | 青(Cyan)、品红(Magenta)、黄(Yellow)、( 黑(blacK) ) | 打印机和印刷设备 |
| HSL 模型 | 色相(Hue)、饱和度(Saturation)、亮度(Lightness) | 由于人的视觉对亮度的敏感程度远强于对颜色浓淡的敏感程度,为了便于颜色处理和识别,人的视觉系统经常采用HSI彩色空间,它比RGB彩色空间更符合人的视觉特性。此外,由于HSI空间中亮度和色度具有可分离特性,使得图像处理和机器视觉中大量灰度处理算法都可在HSI彩色空间中方便地使用。 |
| YUV 模型 | Y 是亮度分量, UV 是色度分量 | 常用在数据传输场景,视频处理组件中, 彩色电视信号传输时使用 |
17. GIF图像有哪些适合网络应用的特性?又有哪些不足?它是如何实现累进显示和动画效果的?
GIF(Graphics Interchange Format)格式由CompuServe公司于87年开发,版本号GIF87a,89年扩充后版本号为GIF89a。 GIF图像文件以块(block)为单位存储信息。一个GIF文件由表示图形/图像的数据块、数据子块以及显示图形/图像的控制信息块��组成 ,称为GIF数据流(Data Stream)。数据流中的所有控制信息块和数据块都必须在文件头(Header)和文件结束块(Trailer)之间。
GIF文件格式的特点
- 颜色数较少(不超过256色) ,文件特别小,压缩比可调,适合网络传输
- GIF文件采用了LZW无损压缩算法来存储图像数据
- GIF文件允许设置背景的透明属性
- GIF文件格式可在一个文件中存放多幅彩色图像并且制作出幻灯片或者动画效果
- GIF文件支持图像数据的交叉存储方式,这样一个大的图像可以逐步显示,让用户首先看到图像概貌,然后逐步清晰 (累进显示)
- GIF文件定义的图像中可以加入文本
它的缺陷和不足是颜色数少, 只有 256 种
累进显示的原理
如果局部图像描述符中的隔行位 (interlace) 被设置, 则图像的行以 4 次分别套色顺序显示。在这里,第一个通道显示第 0 和第 8 行, 第二个通道显示第 4 和第 12 行, 依此类推,通过这个隔行扫描的累进(渐进式, progressive)方式让图像概略迅速显示
GIF 支持隔行扫描 — 通过套色 (four-pass) 显示方法处理, 相隔的像素可以连续显示
动画效果
Jpeg和Jpeg2000的颜色空间是什么
为了减少彩色图像各个分量之间的数据相关性,JPEG2000 与 JPEG一样,通常在预处理时将彩色图像从 RGB 颜色空间变换到 YCrCb 颜色空间。
18. 什么是计算机合成图像?与取样图像相比它有哪些特性?
- 使用算法或几何要素(如点、线、面、体的位置、形状和大小)及表面材料的性质,在计算机中对景物和形体(无论是真实的还是假想的)进行描述(造型modeling)
- 需要显示时,计算机根据观察者的位置及光线的设定,生成该景物的图象(绘制rendering)
合成图像 (矢量图形)
与取样图像相比较
一个是合成媒体,一个是自然媒体,他们的表示方式不同;合成图像需要渲染, 他们的展现方式不同;他们的可编辑性不同
优点
- 缩放、旋转、移动时图像不会失真
- 存储和传输时数据量较小
缺点
- 图像显示时花费时间比较长
- 真实世界的彩色图像难以转化为矢量图
19. 计算机合成图像中什么是造型(建模)?什么是绘制?
- 造型(modeling): 使用算法或几何要素(如点、线、面、体的位置、形状和大小)及表面材料的性质,在计算机中对景物和形体(无论是真实的还是假想的)进行描述
- 绘制(rendering): 需要显示时,计算机根据观察者的位置及光线的设定,生成该景物的图象
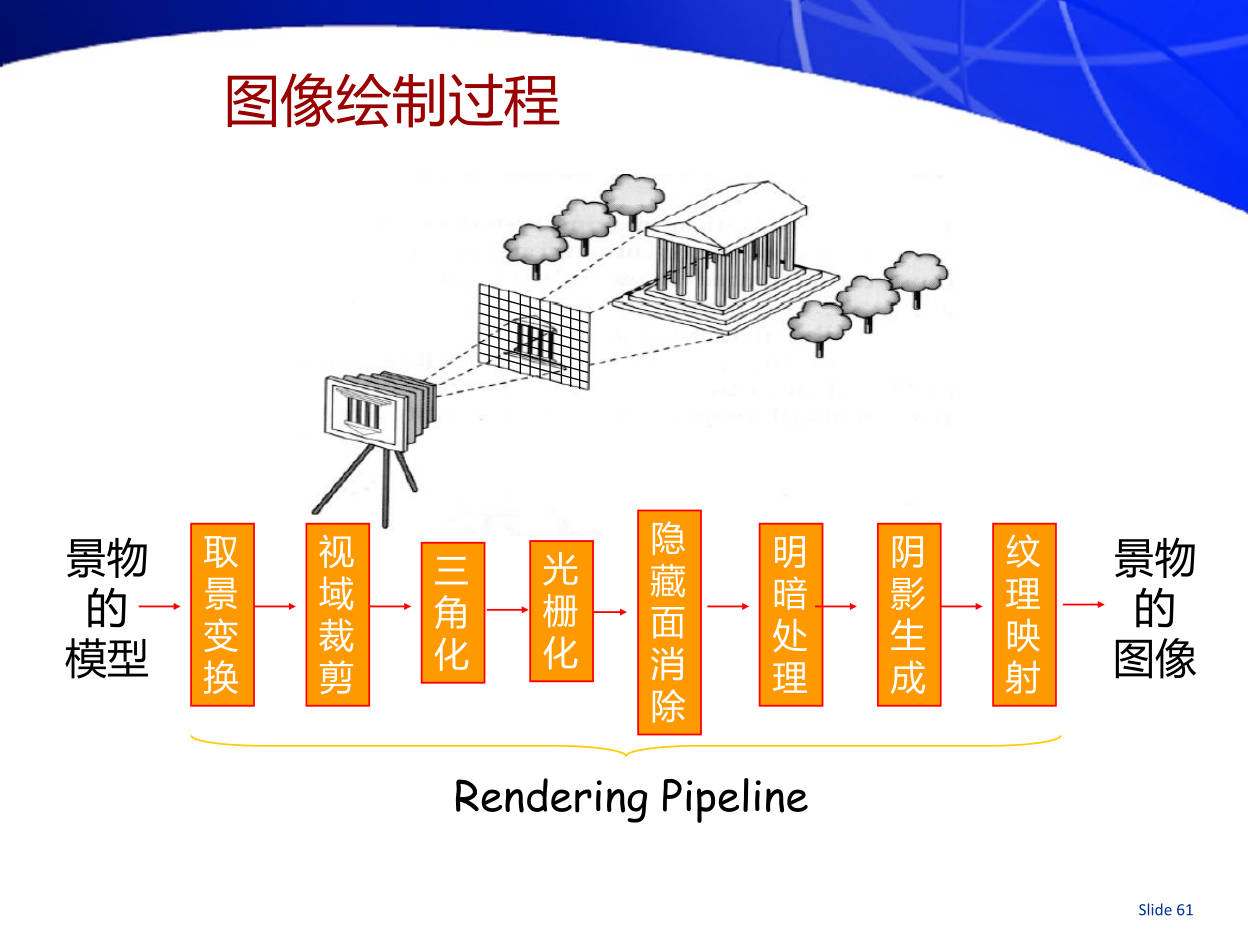
20. 简述合成图像(graphics)的展现过程,需要处理的问题有哪些?
从景物的模型生成具有高度真实感的该景物的图像,此即所谓的图像绘制(rendering),也称为图像合成 (image synthesis)
21. 有损压缩与无损压缩有什么区别?什么情况下必须使用无损压缩?
- lossless(无损压缩)
- run-length coding (RLC)
- 预测编码 ,如JPEG无损编码
- Huffman coding (哈夫曼编码)
- Arithmetic coding (算术编码)
- Lempel-Ziv & Welch coding ( LZW编码, 词典编码 )
- lossy (有损压缩)
- 亚取样
- 变换编码
- 矢量编码
- 特征抽取 (分析-合成法) (模型编码)
两者的区别:
- 还原性上的区别: 无损压缩就是可以完全还原的;有损压缩还原后不能和原来的文件一样,有一定的损耗的
- 压缩率上的区别: 无损压缩压缩率是受到数据统计冗余度的理论限制,一般为2:1到5:1
22. 评价一种压缩编码算法的主要指标有哪些?什么是客观评价法和主观评价法?
数据压缩技术的性能指标:
- 压缩比(compression ratio)
- 压缩倍数
- 压缩效率
- bits per pixel (bpp)
- 算法复杂度
- 计算量/存储量
- 时间延迟(计算延迟、存储延迟)
- 编码/解码算法的对称性
- 重建质量
客观评价法和主观评价法是对重建图像质量的两个评价方法
- 客观评价法
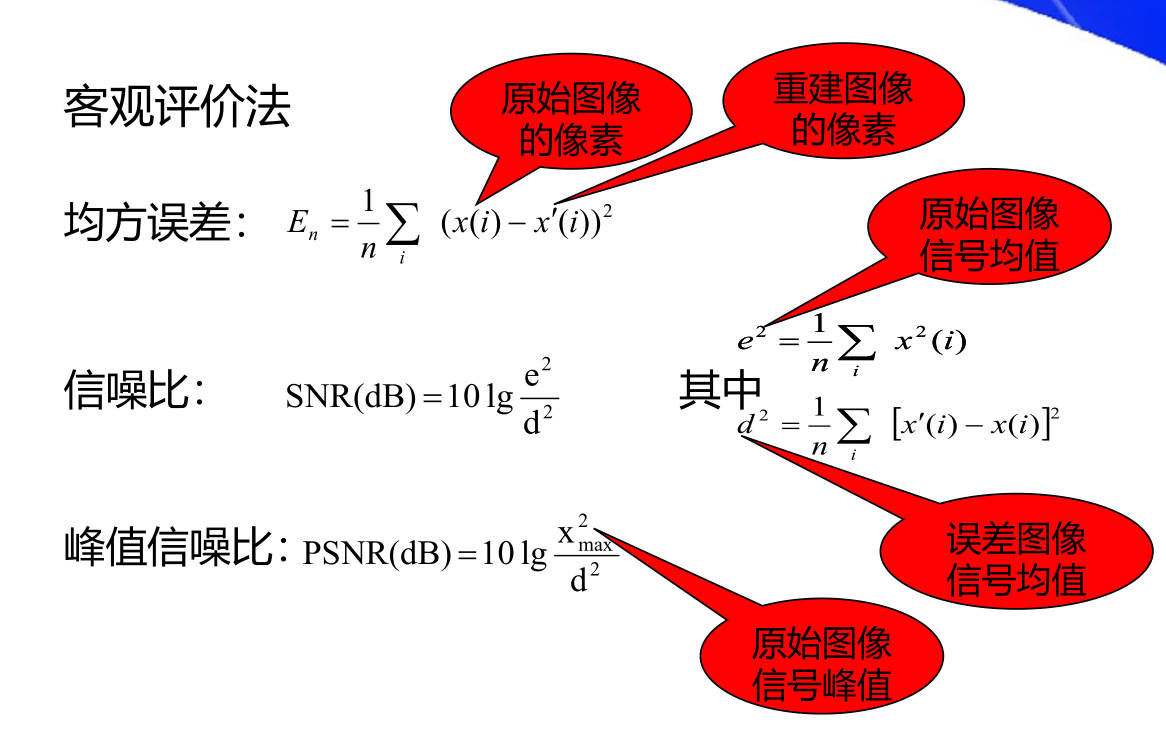
- 主观评价法

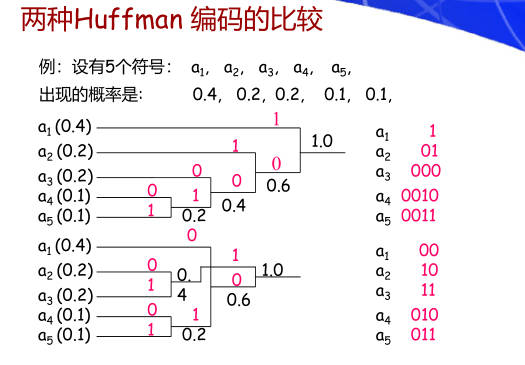
23. 掌握Huffman算法、香农-弗诺编码?
Shannon-Fano算法
- 首先统计出每个符号出现的概率
- 从上到下对上述概率从大到小排序
- 从这个概率集合中的某个位置将其分为两个子集合,并尽量使两个子集合的概率和近似相等,给前面一个子集合赋值为 0, 后面一个子集合赋值为 1
- 重复步骤3,直到各个子集合中只有一个元素为止
- 将每个元素所属的子集合的值依次串起来,即可得到各个元素的香农-范诺编码。
Huffman 编码
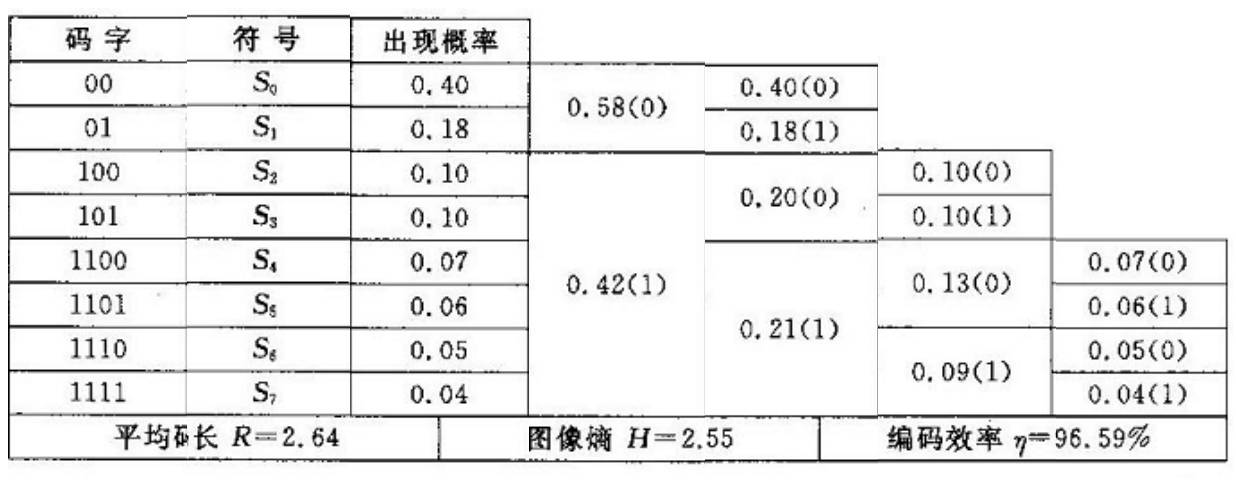
基本原理:将在图象中出现次数多的像素值给一个短的编码,将出现次数少的像数值给一个长的编码。
哈夫曼编码的一般算法如下:
- 首先统计信源中各符号出现的概率, 按符号出现的概率从大到小排序
- 把最小的两个概率相加合并成新的概率, 与剩余的概率组成新的概率集合
- 对新的概率集合重新排序, 再次把其中最小的两个概率相加, 组成新的概率集合。如此重复进行, 直到最后两个概率的和为1
- 分配码字。码字分配从最后一步开始反向进行,对于每次相加的两个概率,给大的赋“0”, 小的赋“1”, 且优先处理未处理过的而不是新生成的(这样深度小,编码短)
从树根开始编码
自适应 Huffman
自适应哈夫曼树满足如下兄弟性质:
-
所有节点按从左到右,自下而上的顺序编号
-
节点编号大的节点,权重值也一定大
而自适应哈夫曼编码的过程就是在编码过程中实时调整哈夫曼树以保证满足兄弟性质
其算法步骤如下:
-
- 建立空哈夫曼树,树的根节点标识为NYT
-
-
读取一个字符
- 当这个字符没有在哈夫曼树里出现过的时候,构建新子树,根节点权重值为1,左孩子为NYT, 右孩子为该字符,用子树替换标识为NYT的节点。同时输出NYT的编码和字符
- 当字符出现过时,输出该字符的哈夫曼编码
-
-
- 从被输出的节点开始往上走,每一个节点权重值加1,但是在加权重值之前,需要判断该节点是否为同权重值里节点编号最大的。如果不是为最大,则与最大节点交换位置(节点的子树也要交换而不是只交换单个节点)。交换后再互换节点编号,这样权重值需要被加1的节点就保证为同级节点编号最大的节点
24. 如果符号A和B出现的概率分别是3/4和1/4,请计算字符串ABABA所对应的子区间及它的编码。如果某字符串的二进制算术编码为0.111111,字符串的长度为5位,该字符串是什么?
25. JPEG顺序编码的过程,如何控制文件大小?
JPEG基于DCT顺序编码的过程
- 预处理,将图像的每个分量均匀划分为若干 8*8 的子块,并进行电平偏移。
- 进行 DCT 变换
- DCT 系数量化
- 通过差分进行直流系数编码
- zig-zag将二维展开到一维并行程长度编码,完成交流系数编码
- 熵编码 (Huffman 编码)
- 组成JPEG比特流
计算
- 直流系数先用定长的 4 个 bit 表示后面的元素长度
- 直流系数定长的 8 个 bit,前 4 个bit 是行程长度, 后 4 个 bit 是元素长度
(a, b)
直流系数最终输出: a的霍夫曼编码, b 照抄
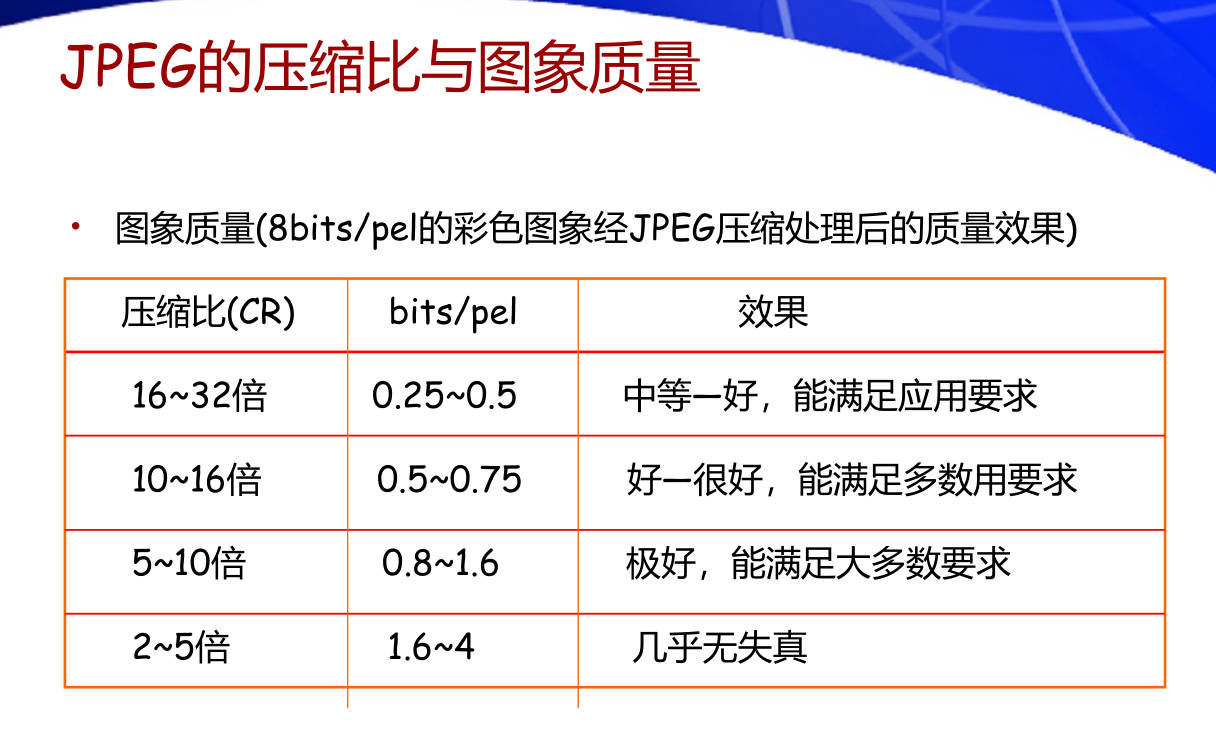
如何控制文件大小
通过控制量化过程的质量因子 Q 可以控制压缩后图像的质量和压缩比

26. 简述基于DCT的累进编码的处理过程。与顺序编码相比它有什么优点,需要的代价是什么?
- 频谱选择法: 先处理直流量
- 连续逼近法: 先处理每个块中 64 个系数的最高比特 (处理最高有效位)
优点是可以给用户一个整体的低分辨的模型,缺点是需要更大的内存、更长的时间和更大的码率
27. 简述基于DCT的层次编码的处理过程。它有什么优点,需要的代价是什么?
- 把原始图象分辨率逐级降低(subsampling),得到一组分辨率由低到��高的图象
- 把分辨率最低的图象进行 JPEG 压缩编码
- 解码,重建该图象。然后用插值方法提高其分辨率,作为高一级分辨率原始图象的预测图象
- 求出预测图象与相应原始图象的差值图象,对差值图象进行 JPEG 压缩编码
- 重复 3 和 4,直到达到原始图象最高分辨率为止
它的优点或目的是高分辨率图像在任意分辨率设备上输出(scalable),由粗到精; 代价是计算和存储的复杂度
28. Haar小波分解的原理,嵌入零树小波系数编码算法
嵌入零树小波系数
- 零树根 t:
- 孤独零 z:
- 正大系数 p: 如果是正数且大于阈值,则是 p
- 负大系数 n: 如果是负数且绝对值大于阈值,则是 n
逐次逼近量化(SAQ)
数据结构用到两个表:
- 主表:编码中的不重要系数,其输出信息起到了恢复各重要值的空间位置结构的作用
- 辅表:编码中的重要系数,输出值为重要系数的二进制值
编码分为主、辅两个过�程:
- 主过程中,设定阈值为 ,其中 为不大于表中所有系数的绝对值的最大值的二次幂 ,按顺序对主表进行扫描编码,若是重要系数,则将其加入辅表中,然后将该系数置零。
- 辅过程中,对辅表中的重要系数进行细化,若系数位于 ,则用 0 表示,否则用 1 表示
29. 什么是视频信号的时间特性和空间特性,它们有哪些主要参数?
时间特性
- 动作连贯性感觉的要求:帧频 >= 15 f/s;
- 无闪烁感觉的要求:场频(垂直扫描频率, 即画面刷新速率)必须 >= 每秒 50 次
- PAL 制式:帧频为 25 帧/s, 场频是 50/s
- NTSC 制式:帧频是 30 帧/s, 场频是 60/s
- 电视扫描信号的行频
- PAL:625 x 25 = 15.625 kHz ,周期为 64 μs
- NTSC:525 x 30 = 15.75 kHz,周期为 63.5 μs
- 模拟信号传输电视节目时的带宽
- PAL 制式是 8.0 MHz(亮度信号为 5.5 MHz,2 个色度信号均为 1.8 MHz)
- NTSC 制式是 6.0 MHz(亮度信号为 4.2 MHz,2 个色度信号均为 1.0 MHz)
空间特性
- 有效行数(垂直分辨率)
- PAL 制式:扫描线为 625 行, 其中可见 575 行 (帧正程)
- NTSC 制式:扫描线为 525 行, 其中可见 485 行 (帧正程)
- 长宽比(纵横比): 一般为 4:3 或 16:9
30. 彩色电视信号有哪3种类型,它们的信号质量及适用范围怎样?
复合分离分量
| 信号 | 质量 | 适用范围 |
|---|---|---|
| 复合电视信号 | VHS (家用级) | 适合于进行远距传输 |
| 分量电视信号 | Betacam(广播级, 专业级) | 近距离传输,视频节目制作,计算机输出的视频信号 |
| 分离 (S-Video) 信号 | 是前两者的折中方案 |
彩色电视制式(注意对比)
- NTSC制 (正交平衡调幅制), 美国、加拿大,台湾、日本、韩国、菲律宾等采用
- PAL制 (逐行倒相正交平衡调幅制), 德国、英国,中国、朝鲜等采用
- SECAM制 (顺序传送彩色与存储制), 法国、苏联及东欧国家采用.
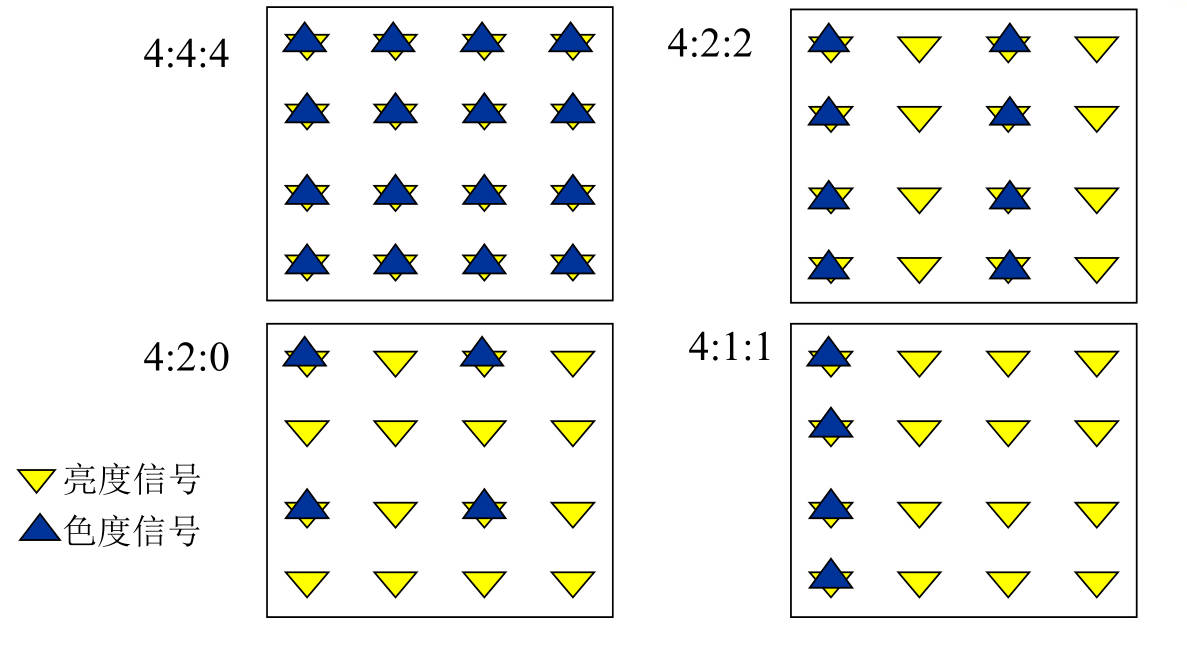
31. 色度信号的取样格式有哪几种?不同取样格式情况下每个像素的平均样本数是多少?
-
人对颜色的敏感程度远不如对亮度信号那么灵敏,所以色度信号的取样频率可以比亮度信号的取样频率低,以减少数字视频的数据量
-
色度信号的取样频率有4种
| 格式 | 取样频率 | 平均每个像素的样本数 | 描述 |
|---|---|---|---|
| 4:4:4 | 同亮度信号取样频率 | 3 样本/像素 | 每1个像素都有1个y, 1个u和1个v |
| 4:2:2 | 亮度信号取样频率的 1/2 | 2 样本/像素 | 每1个像素有1个y, 每2个像素共用1个u和1个v |
| 4:1:1 | 亮度信号取样频率的 1/4 | 1.5 样本/像素 | |
| 4:2:0 | 亮度信号取样频率的 1/2,但隔行处理 | 1.5 样本/像素 | 每1个像素有1个y, 每4个像素共用1个u和1个v |
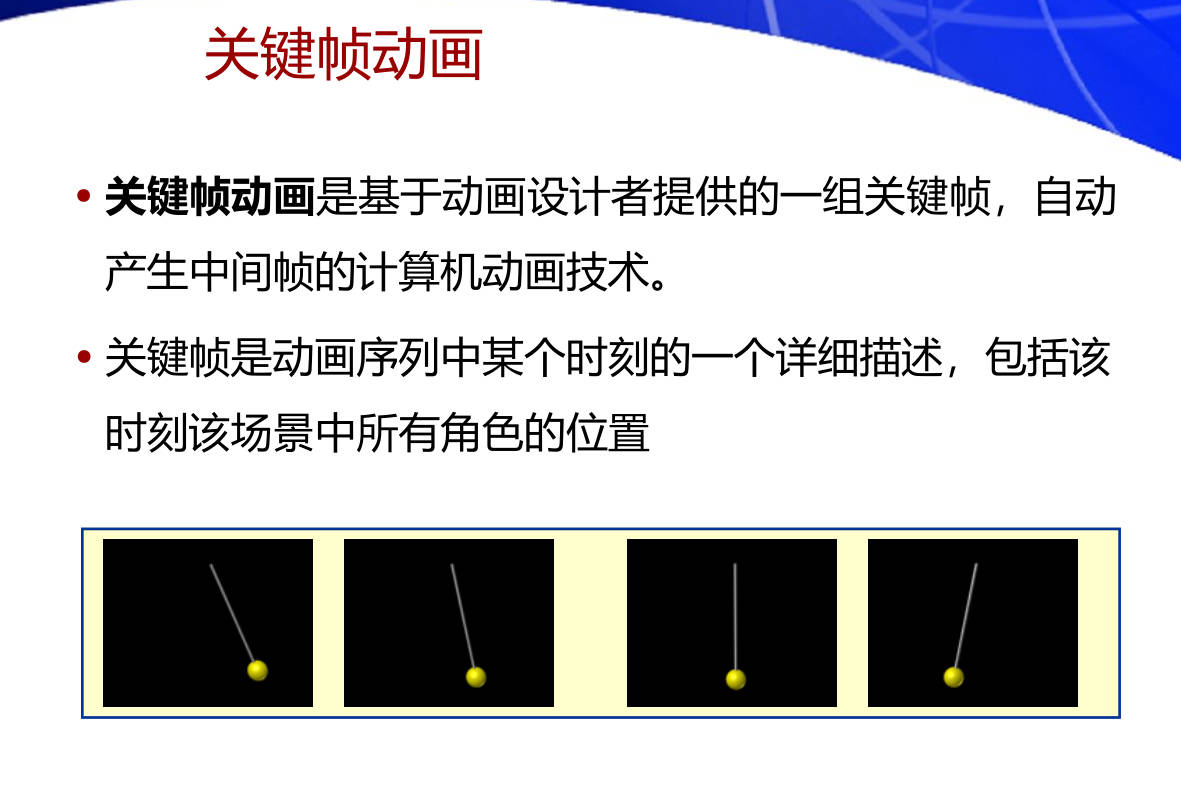
32. 请简述计算机动画中有哪几种运动控制方法以及各自的优缺点
关键帧 (Keyframing)
计算法(Procedural and Simulation)

运动捕获技术

重用以前的动作
33. MPEG 专家组制定的国际标准有哪些?制定这些标准的目的分别是什么?
| 标准 | 目的和应用 |
|---|---|
| MPEG-1 | 用于1.5Mbps数据传输率的运动图像及其伴音的编码,主要应用于 VCD,MP3 音乐等 |
| MPEG-2 | 主要针对数字电视特别是高清晰度电视 (HDTV) 的视频及伴音信号,与MPEG-1兼容,典型传输速率为10Mbps,适用于1.5Mbps~60Mbps甚至更高速率的编码范围 |
| MPEG-4 | 基于对象的视(音)频编码标准,目标是支持各种多媒体应用(��主要侧重于对多媒体信息内容的访问) |
| MPEG-7 | 规定 "多媒体内容描述接口"标准, 该标准将确定各种类型的多媒体信息的标准描述方法 |
| MPEG-21 | 是一个支持通过异构网络和设备使用户透明而广泛地使用多媒体资源的标准,其目标是建立一个交互的多媒体框架 |
MPEG-1
- MPEG-1标准(ISO/IEC11172). 1992年发布。用于1.5Mbps数据传输率的运动图像及其伴音的编码。主要应用于 VCD,MP3 音乐等
- MPEG-1在 JPEG 和 H.261 等优秀标准的基础上, 对参加竞争的 14个 方案,通过反复协调而得到统一,从而成为先进、合理、质量高、成本低的优秀标准
- MPEG-1 促进了大规模集成电路专用芯片的发展, 为多媒体技术和产品的繁荣立下了功劳
MPEG-2
MPEG-2标准(ISO/IEC13818). 1994年发布。主要针对数字电视特别是高清晰度电视 (HDTV) 的视频及伴音信号,典型传输速率为10Mbps,与MPEG-1兼容,适用于1.5Mbps~60Mbps甚至更高速率的编码范围
- 以MPEG-2作为视音频压缩标准的数字卫星电视已在欧美形成了很大市场
- 美国高级电视联盟 (ATV Grand Alliance) 和欧洲数字视频广播计划 ( Digital Video Broadcast Project) 先后决定将 MPEG-2 用于**高清晰度电视(HDTV)**广播中
- 新一代的数字视盘DVD采用 MPEG-2 作为其视音频压缩标准 (注:欧、美 、日在视频方面采用 MPEG-2 标准,而在音频方面则采用 AC-3 标准)
MPEG-4
MPEG-4 标准(ISO/IEC l4496) . “Coding of audio-visual objects”1999年5月形成国际标准(版本1), 2001-2002形成版本2,是一种基于对象的视(音)频编码标准,目标是支持各种多媒体应用(主要侧重于对多媒体信息内容的访问)
其主要目标是 “compression and manipulation of audio and visual objects, the web page paradigm applied to audio and video!”
MPEG-7
MPEG-7标准(ISO/IEC l5938) 于 2001年9月形成。 它是“多媒体内容描述接口”(Multimedia Content Description Interface)的标准, 该标准将确定各种类型的多媒体信息的标准描述方法, 可应用于数字图书馆、各种多媒体目录服务、广播媒体的选择,以及多媒体编辑等领域。
MPEG-21
MPEG-21 总体上来讲是一个支持通过异构网络和设备使用户透明而广泛地使用多媒体资源的标准,其目标是建立一个交互的多媒体框架。支持以下功能:
- 通过网络和/或设备存取、使用并交互操作多媒体对象
- 实现多种业务模型,包括在价值链中对版权和支付交易的自动管理
- 对内容使用者隐私的尊重
MPEG-21 技术报告向人们描绘了一幅未来的多媒体环境场景,这个环境能够支持各种不同的应用领域,不同用户可以使用和传送所有类型的数字内容
34. MPEG-1对视频图像是如何进行预处理的,其目的是什么?
- 从RGB 到 YCbCr 的颜色空间变换
- 格式转换
- 预滤波
目的:降低分辨率,色度采样格式,分块,灰度值调整
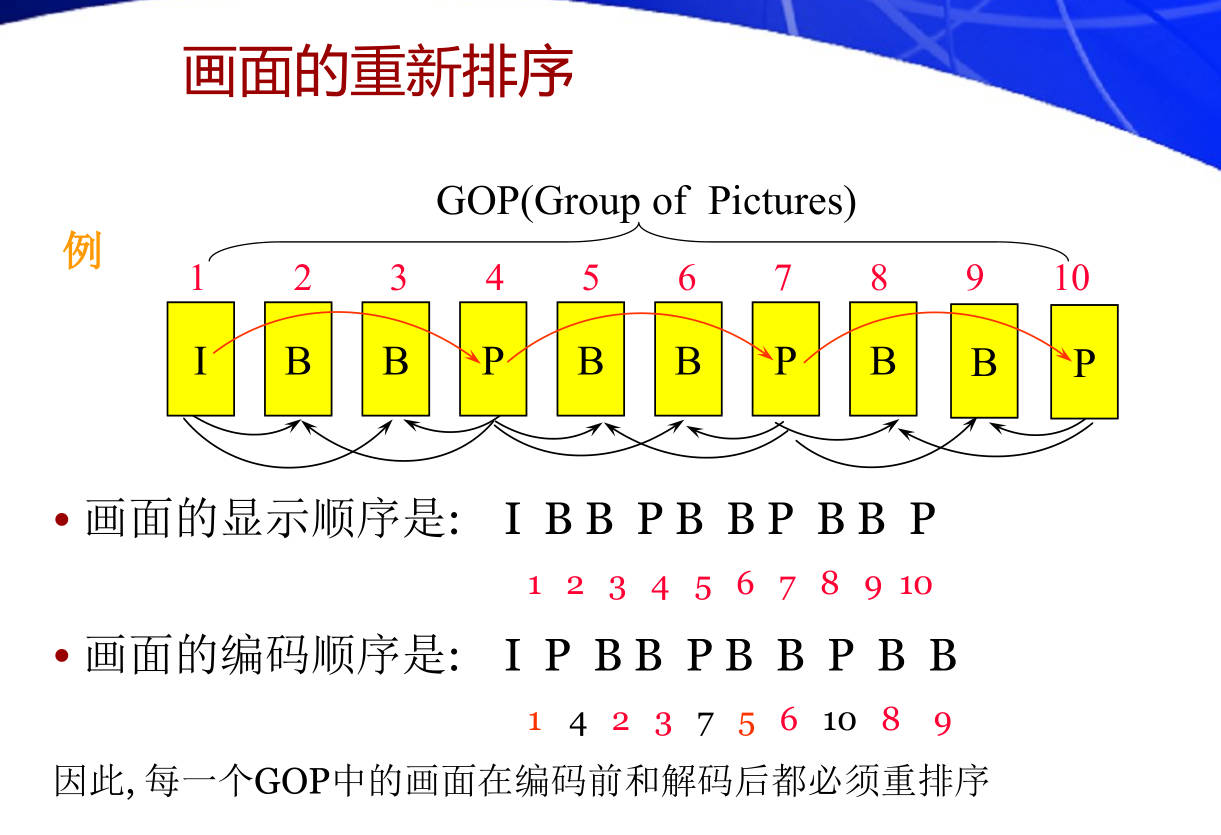
35. 视频画面在MPEG-1中是如何分组(GOP)的? 画面分成哪几类? 编(解)码时如何对画面进行重新排序?
画面的分类
- Intra-picture ( I画面 ) 不需要参考其它画面而独立进行压缩编码的画面
- Predicted-picture ( P画面 ) 参考前面已编码的 I 或 P画面进行预测编码的画面
- Bidirectional-picture ( B画面 ) 既参考前面的I或P画面、又参考后面的I或P画面进行双向预测编码的画面
- DC coefficient-picture ( D画面 ) 仅使用画面中每个块的 DC系数进行编码, 用作正/反向快速搜索.单独进行编码与存储(仅MPEG-1使用)
分组(GOP)和重新排序
B 帧后面的 P 帧在编码和解码时要移到其前面

36. 什么是宏块? 什么是运动矢量?
在视频编码中,一个编码图像通常划分成若干宏块组成,一个宏块由一个亮度像素块和附加的两个色度像素块组成。一般来说,亮度块为16x16大小的像素块,而两个色度图像像素块的大小依据其图像的采样格式而定,如:对于YUV420采样图像,色度块为8x8大小的像素块。每个图象中,若干宏块被排列成片的形式,视频编码算法以宏块为单位,逐个宏块进行编码,组织成连续的视频码流。
在帧间编码中,用运动矢量(MotionVector,MV)表示当前编码块与其参考图像中的最佳匹配块之间的相对位移。每个划分的块都有相应的运动信息需要传送到解码端。如果对每个块的MV进行独立编码和传输,特别是划分成小尺寸的块,需要消耗相当多的比特。
画面各处的运动矢量(幅度、方向)各不相同,因此,画面应细分成块(宏块),以宏块为单位,找出两帧画面中相应宏块之间的位移关系——运动矢量
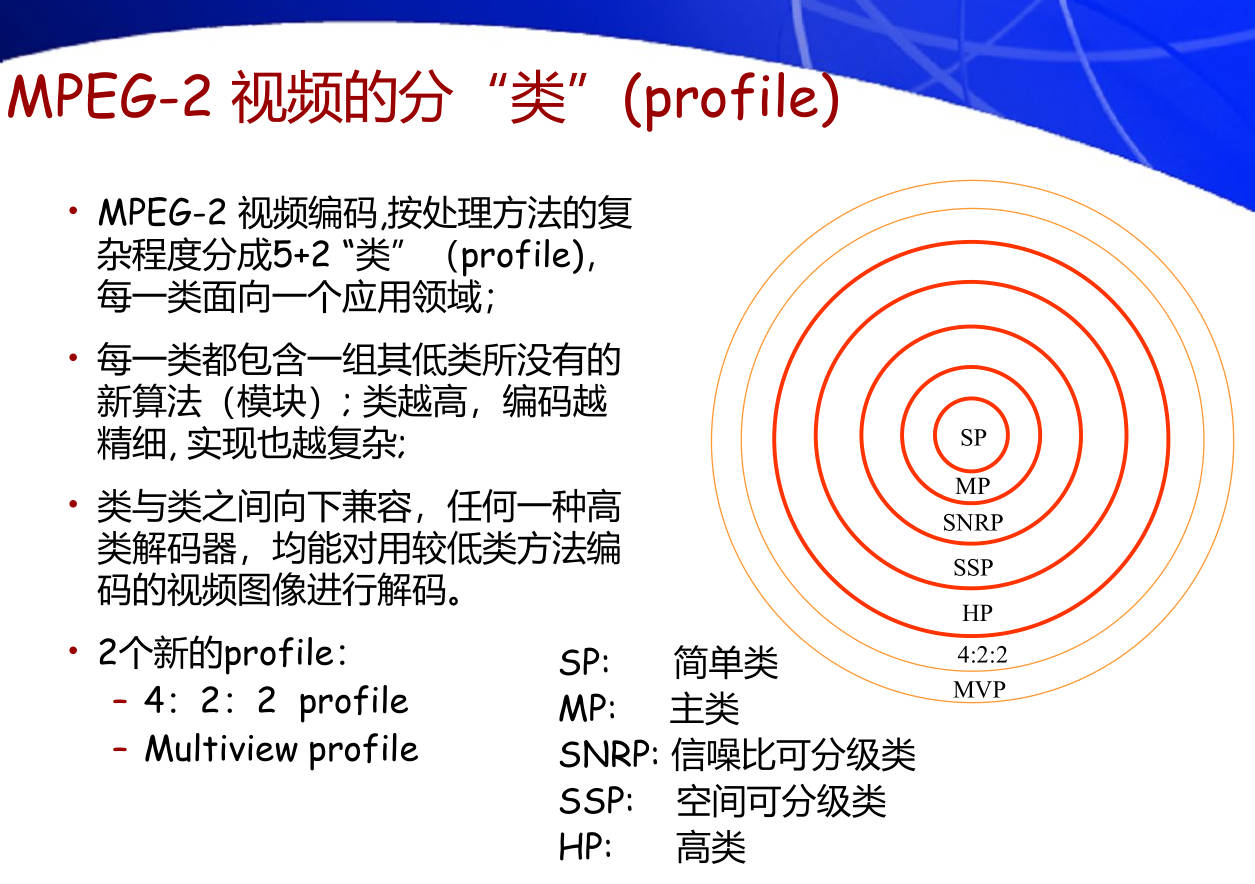
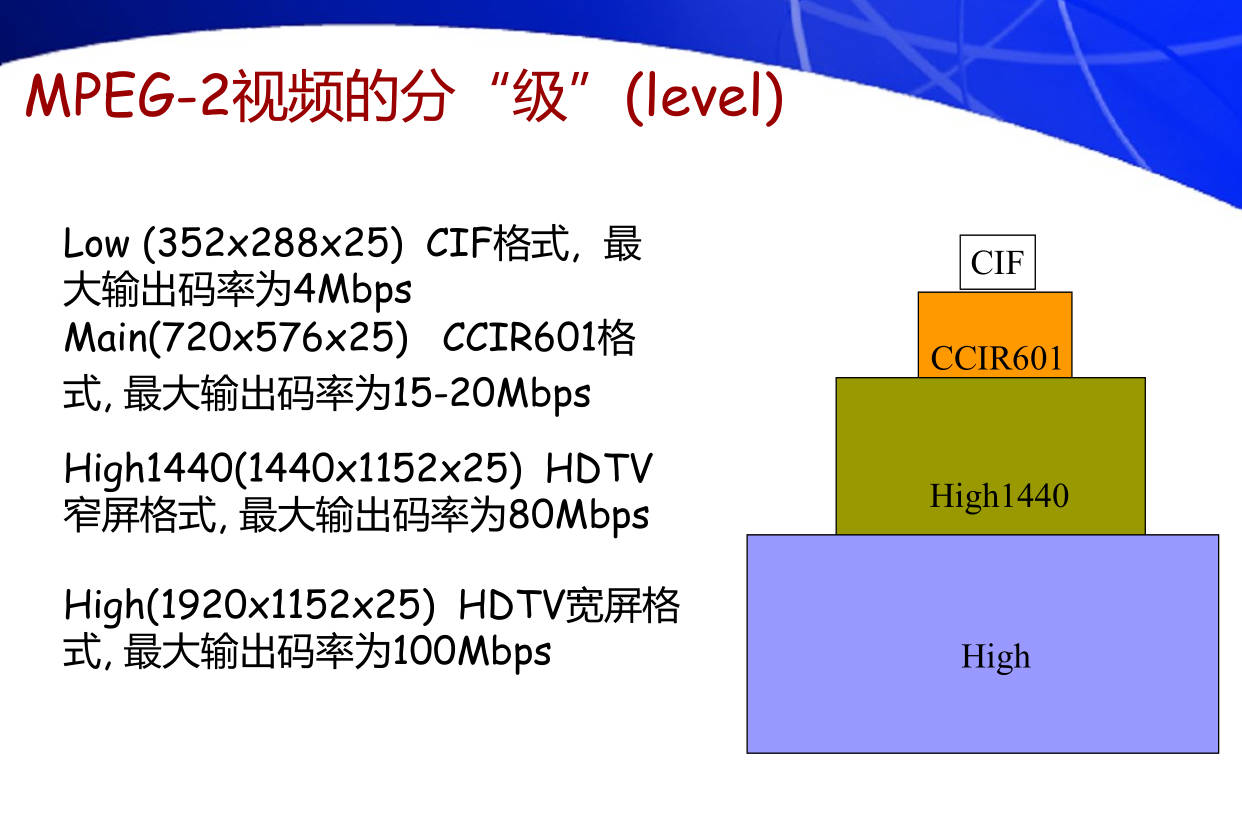
37. MPEG-2视频的压缩编码是如何分"类"(profile)和分"级"(level)的? 分成哪些类和级?

38. MPEG-4 中可视媒体对象指什么?MPEG-4可视对象编码有哪些功能?MPEG-4的合成对象有哪些?
合成对象
MPEG-4 的可视媒体对象指图片中拥有相关联的形状,纹理(颜色)和动作的最小实体
MPEG-4可视对象编码的功能:
- 可以集成各种对象,无缝地集成自然媒体(源于麦克风、摄 象机等)与人造媒体(计算机生成) 、实时信息与存储信息, AV0可以是单/双/多声道音频信息、单/双/多镜头2D /3D视频信息。
- 提供更强的交互能力,场景中的对象(人、桌子、地球仪、 白扳、人的声音)以及多媒体演示声音均作为单个对象而独 立编码,用户可以有选择地与其中某(几)个对象交互。
- 具有良好的重用性,可重新组合音视对象 AVO (Audio Visual Object)构造新场景。
MPEG-4 的合成对象有二维网格,三维网格,midi